

Resources
Test, Tune, Repeat: The Real World Guide to Building and Scaling AI Voice Agents
Part 2: Navigating the Chaos: Testing Voice Agents in the Real World

July 7, 2025
4 minutes
Test, Tune, Repeat: The Real World Guide to Building and Scaling AI Voice Agents**
In Part 1, we established the technical foundation of an AI voice agent. Now, we confront the most formidable challenge: ensuring it works reliably in the messy, unpredictable real world. Testing a voice agent isn't like testing a website. You aren't checking buttons and forms; you are validating a system designed to interpret the infinite complexity of human speech.
Every voice agent operates within a "Cloud of Problems"—a swirling vortex of linguistic, environmental, and technical variables that can degrade performance and lead to failure. A simple "happy path" test is insufficient. To build a truly robust agent, you must proactively test against this chaos.
The Cloud of Problems: Why Testing Voice AI Is So Hard
These are the core challenges, drawn from real-world deployments, that make rigorous testing essential.
- Non-Deterministic Behavior: Unlike traditional software that gives a predictable output for a given input, voice AI is probabilistic. The same question, asked with a slight variation in tone or phrasing, might yield a different response. Success isn't a simple pass/fail; it's a measure of probability and consistency.
- Real-World Speech Variability: Humans don't speak like sterile audio recordings. A production agent must handle:
- Accents and Dialects: An agent tuned only on standard American English might misinterpret an Indian-English speaker saying "thirty" as "thirteen."
- Background Noise & Poor Call Quality: A customer might be calling from a busy street with honking horns, or on a crackling phone line where parts of sentences are lost. The agent must filter noise and handle partial utterances.
- Speaking Styles and Quirks: Users may speak very fast or slow, use slang, mumble, or pause frequently. A cough or a laugh mid-sentence can be misinterpreted as a word, derailing the conversation.
- Accents and Dialects: An agent tuned only on standard American English might misinterpret an Indian-English speaker saying "thirty" as "thirteen."
- Cascading Errors Across the Pipeline: The modular nature of a voice agent is also its weakness. An error in one component creates a domino effect. A small ASR transcription error can cause the LLM to completely misunderstand the user's intent, leading the TTS to confidently speak a nonsensical answer. Pinpointing the root cause is incredibly difficult without a structured testing approach.
- The Moving Target of Continuous Evolution: Voice agents are not static. A simple change—like updating the system prompt, fine-tuning the LLM, or changing the TTS provider—can cause **unexpected regressions**, breaking responses that were working perfectly last week. Continuous testing is the only way to catch this deterioration.
The Solution: The VocalGuard Pipeline for Proactive Testing
To navigate this "Cloud of Problems," teams need a disciplined, shift-left testing strategy. The VocalGuard Pipeline provides this structure, turning testing from a final-stage QA check into a continuous process that builds quality in from the start. It is a funnel designed to systematically address the challenges of voice AI. It treats testing not as a final step, but as a continuous process funneling a use case from an idea into a monitored, production-grade system.
The Testing Funnel: From Blueprint to Production
The VocalGuard Pipeline is a multi-stage funnel that ensures quality at every phase of development.
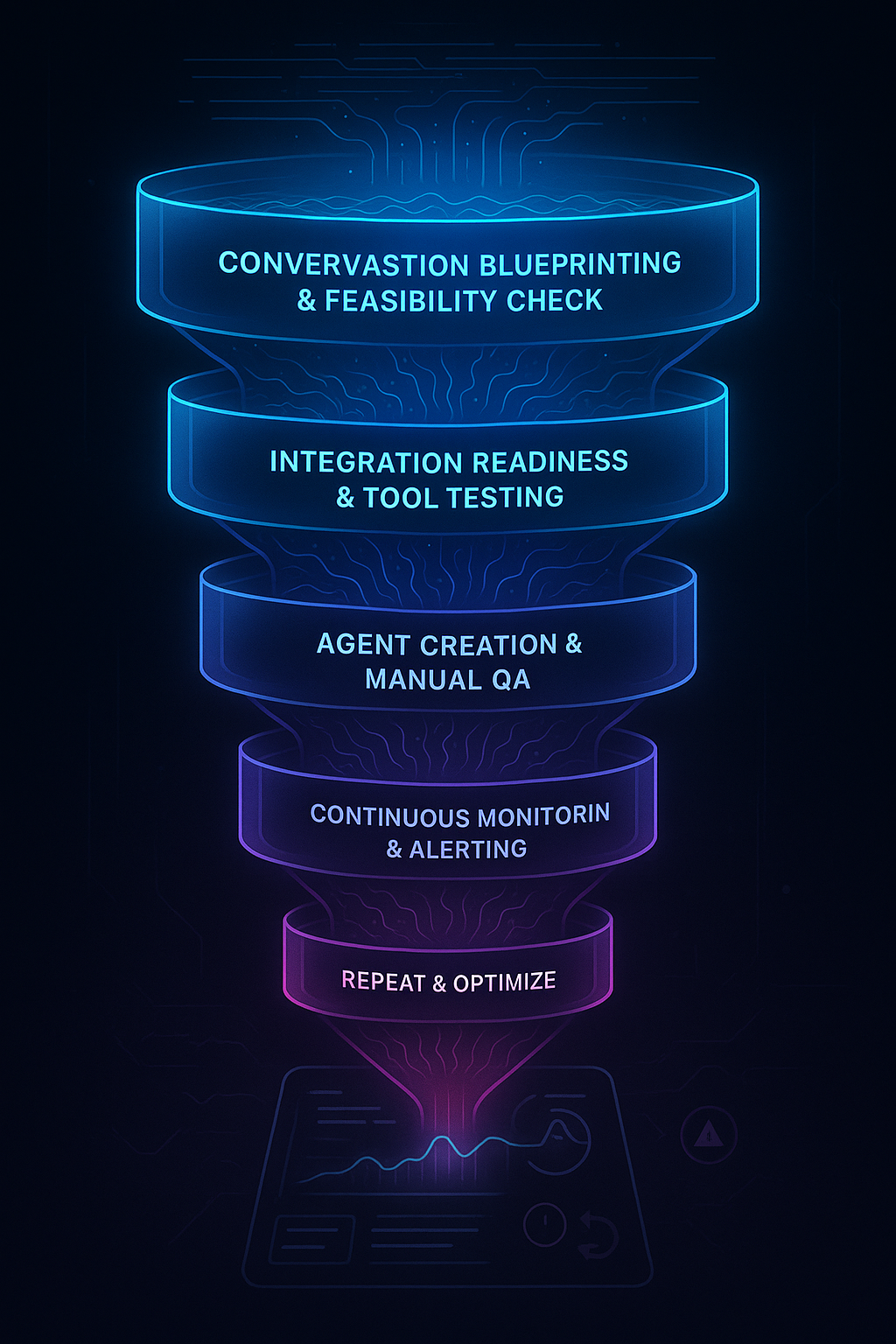
Stage 1: Conversation Blueprinting & Feasibility Check
Before you build anything, you must understand the existing conversation.
- Objective: To map the actual paths that human conversations follow and determine if the use case is a good fit for AI.
- Process:
- Analyze Real Conversations: Use call recordings and transcripts from live agents to identify the most common user intents, questions, and outcomes. Don't rely on idealized scripts.
- Visualize the Flow: Use manual mapping or AI-based Call Path Analysis to create a visual representation of how conversations flow. A Sankey diagram is excellent for this, showing where users drop off or get transferred.
- Validate with Business Teams: Collaborate with stakeholders to confirm that your understanding of the call paths aligns with business goals.
- Check Feasibility: Evaluate whether the intended task is suitable for an AI agent. Is the conversation predictable? Does it involve emotionally sensitive topics or complex compliance issues that require a human? Scenarios with legal ramifications, for instance, should immediately trigger a human fallback.
- Analyze Real Conversations: Use call recordings and transcripts from live agents to identify the most common user intents, questions, and outcomes. Don't rely on idealized scripts.
Stage 2: Integration Readiness & Tool Testing
A voice agent's real power comes from its ability to interact with other systems. Voice AI success is good tool orchestration.
- Objective: To validate all API integrations and plan for failure.
- Process:
- Validate API Connections: Thoroughly test the agent's ability to connect to and exchange data with any required external systems, such as a CRM, booking calendar, or order management database.
- Test Edge Cases: Don't just test the "happy path." Simulate what happens when an integration fails.
- API Timeout: What does the agent say if a database takes too long to respond? It should be something like, "This is taking a little longer than usual, please hold on."
- API Failure: What happens if the API returns an error? The agent must have a graceful fallback, such as, "I'm having trouble fetching that information right now. Let me connect you to someone who can help."
- API Timeout: What does the agent say if a database takes too long to respond? It should be something like, "This is taking a little longer than usual, please hold on."
- Confirm Success Cases: Ensure that successful API calls result in a clear, confirmatory message to the user: "Great, I've booked your appointment for 10 AM tomorrow."
- Validate API Connections: Thoroughly test the agent's ability to connect to and exchange data with any required external systems, such as a CRM, booking calendar, or order management database.
Stage 3: Agent Creation & Manual Functional QA
This is where the agent is built and its core logic is tested.
- Objective: To build a functional agent with robust logic and test it against the defined conversation paths.
- Process:
- Build with Fallbacks: Construct the agent with tool-linked flows, robust fallback detection (for when it gets confused), and clear recovery logic.
- Choose Best-Fit Models: Select the ASR, LLM, and TTS models that best suit your use case (e.g., Deepgram + GPT-4o + ElevenLabs).
- Test for Regressions: Every time a model is updated or a prompt is changed, you must **re-test the entire conversation path.** A small tweak to a prompt can cause unexpected changes in behavior (regressions).
- Test for Guardrail Violations: Actively try to break the agent. Test for prompt injection, attempts to bypass instructions ("escape phrases"), and other failure modes.
- Build with Fallbacks: Construct the agent with tool-linked flows, robust fallback detection (for when it gets confused), and clear recovery logic.
Stage 4: Continuous Monitoring & Alerting
Once deployed, an agent's performance must be continuously measured.
- Objective: To track the agent's real-world performance against key metrics and alert the team when issues arise.
- Process:
- Define Unique Metrics: Every agent has different goals. A "Billing Assistant" might track the percentage of successful invoice lookups, while an "Appointment Booker" would track booking completion rates. Other key metrics include transfer ratio (how often it hands off to a human) and resolution time.
- Analyze Impact: Use STT logs, call outcomes (e.g., "Objective met" vs. "Objective not met"), and sentiment analysis to measure the agent's impact on the user experience.
- Set Up Alerts: Create automated alerts for critical events, such as:
- A sudden drop in the resolution rate.
- A spike in fallback handoffs to human agents.
- Agent response latency exceeding a defined threshold (e.g., >2 seconds).
- Define Unique Metrics: Every agent has different goals. A "Billing Assistant" might track the percentage of successful invoice lookups, while an "Appointment Booker" would track booking completion rates. Other key metrics include transfer ratio (how often it hands off to a human) and resolution time.
By adopting the VocalGuard Pipeline, you shift from a reactive "test and fix" model to a proactive "design for quality" approach. This ensures that by the time your agent interacts with a real user, it is not only functional but also resilient, reliable, and aligned with real-world needs.
In the final part of this series, we will cover rollout strategies and how to manage customer expectations to ensure a smooth and successful deployment.