

Resources
Test, Tune, Repeat: The Real World Guide to Building and Scaling AI Voice Agents
Part 1: From Voice to Value: Understanding the AI Voice Agent Stack

July 7, 2025
4 minutes
Test, Tune, Repeat: The Real World Guide to Building and Scaling AI Voice Agents
Voice AI agents are rapidly moving beyond simple command-and-response systems like Siri and Alexa to become powerful, autonomous platforms capable of handling complex, natural conversations. In 2025, industries from finance to healthcare are deploying these agents to automate workflows, enhance customer interactions, and operate 24/7. But building a voice agent that performs reliably in the messy, unpredictable real world requires a deep understanding of its underlying technology. This article, the first in a three-part series, breaks down the essential components of a modern voice AI agent, explains why certain architectures prevail, and sets the stage for building and testing them effectively.
Core Components: The Anatomy of a Voice Agent
A voice AI agent's ability to hear, think, and speak relies on a pipeline of specialized technologies working in concert. This modular approach is the current standard for building production-grade voice agents. Here’s a look at the core components:
- Hear (Automatic Speech Recognition - ASR): Often called Speech-to-Text (STT), this is the agent's "ear." It captures the user's spoken words and transcribes them into text. The quality of the ASR is critical, as any error here will cascade down the entire pipeline.
- Think (Natural Language Understanding & Response): This is the agent's "brain." A Large Language Model (LLM) or a dialog manager processes the transcribed text to interpret the user's intent. It decides on the appropriate response or action, which may involve calling external tools or APIs to fetch data like an order status or to execute a command like booking an appointment.
- Speak (Speech Synthesis - TTS): This is the agent's "voice." The Text-to-Speech component converts the LLM's text-based response back into audible, natural-sounding speech to be played back to the user.
This sequence of **ASR → LLM/NLU → Tool Calls → TTS** forms the foundational pipeline of most modern voice agents.
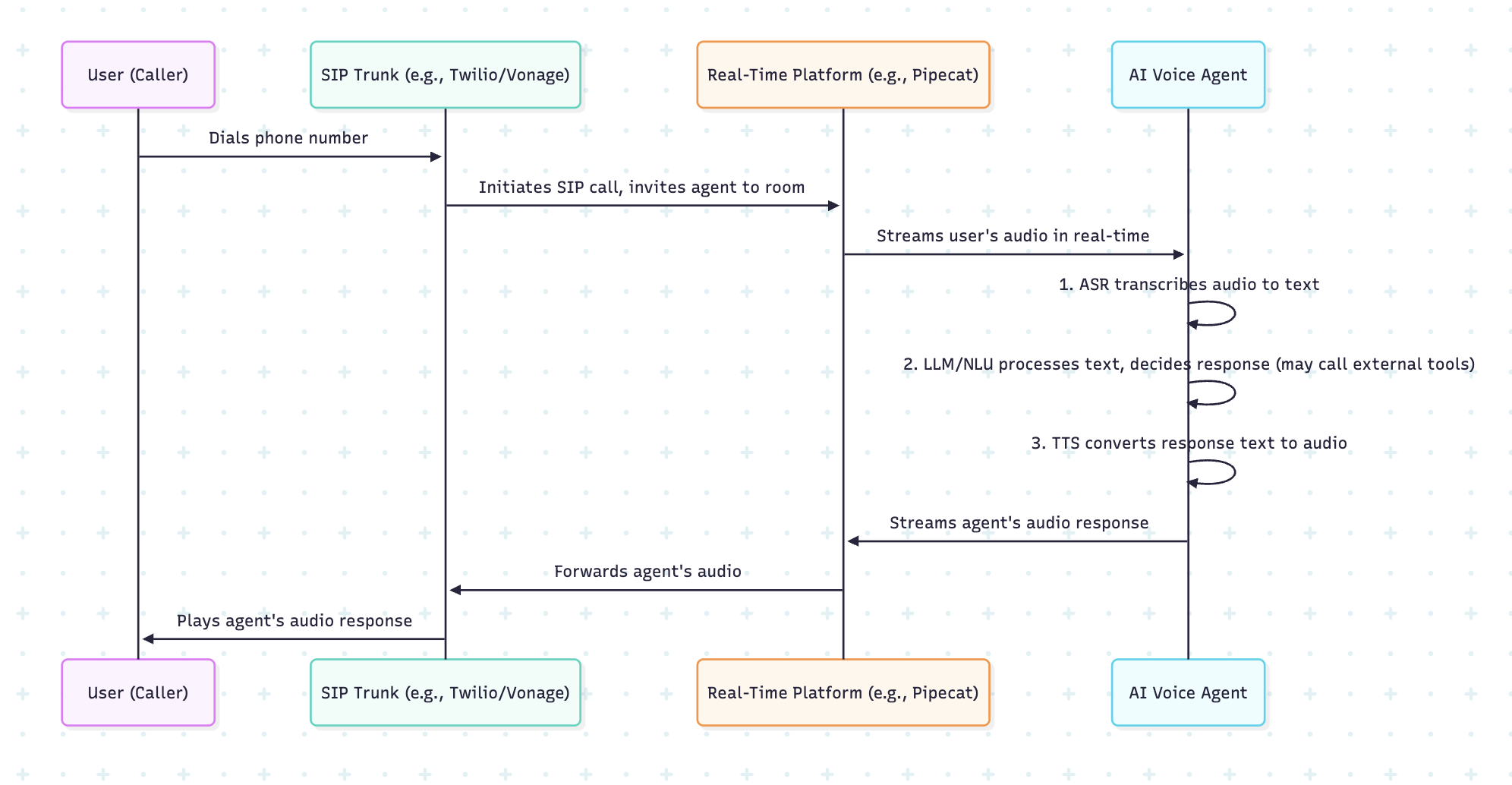
The Real-World Call Pipeline: SIP and Real-Time Communication
To function in a business context, such as a call center, a voice agent needs to connect to telephony systems. This is often accomplished using the Session Initiation Protocol (SIP), a standard that bridges traditional phone networks with the digital world where the voice agent operates.
Platforms like LiveKit, Pipecat are used to manage the real-time flow of audio. In this environment, every entity in a call—the human user and the AI agent—is treated as a "participant" in a digital room. This allows for seamless orchestration of the conversation, ensuring audio is routed correctly and in real-time.
Here's a simplified visualization of the end-to-end call flow:
Why the Traditional Pipeline Still Dominates Over Real-Time STS
An emerging technology called end-to-end Speech-to-Speech (S2S) aims to transform input audio directly into output audio, bypassing the intermediate text steps. These models show great promise in preserving more of the nuance of human speech, like tone and emotion, while reducing latency.
However, in 2025, the "chained" or modular ASR → LLM → TTS pipeline remains the dominant architecture for most production use cases for several key reasons:
- Best-of-Breed Optimization: The modular approach allows developers to select the best-performing tool for each part of the pipeline. One might use a highly accurate ASR from a specialized provider, a powerful LLM from another, and a very natural-sounding TTS from a third.
- Control, Guardrails, and Debugging: The separation of components makes it easier to implement controls and debug issues. If a response is poor, developers can inspect the output of each stage (the ASR transcript, the LLM's reasoning) to pinpoint the source of the error. End-to-end models can be more of a "black box," making them harder to troubleshoot and guardrail.
- Stability and Maturity: The traditional pipeline is a well-understood, stable architecture that has been battle-tested and optimized for production environments. While S2S technology is advancing rapidly, it is still facing challenges in reliability and control for most enterprise-level deployments.
Setting the Right Expectations: Voice Agent ≠ Human Replacement
A common pitfall when adopting voice AI is to view an agent as a direct, one-to-one replacement for a human. This sets unrealistic expectations. The most successful voice agent implementations treat them as efficiency boosters that augment human staff. They excel at handling routine, high-volume queries, which frees up human agents to focus on more complex, emotional, or sensitive issues.
For this reason, it's crucial to start with a narrow and predictable use case. Automating simple, well-defined tasks like checking an account balance, scheduling an appointment, or handling a basic product inquiry provides a clear path to success and minimizes risk. Once the agent proves itself in a limited scope, its capabilities can be gradually and safely expanded.
In the next part of this series, we will introduce the "VocalGuard Pipeline," a shift-left testing strategy designed to ensure your voice agent is reliable and effective from the very beginning of its development lifecycle.